User's guide
Zenobe users Guide
System Overview
- Manufacturer: Bull Atos
- 15 racks, 19 chassis equipped with 171 blades BullX B510 and 14 chassis equipped with 120 blades BullX B520
- 407.7 Tflop/s peak cluster
- 332.5 Tflop/s LINPACK
- TOP500 List zenobe
- Total CPU cores: 13968
- Total memory: 39168 GB
| Nodes details | ||
|---|---|---|
| Blade types | BullX B520 | BullX B510 |
| Node types |
Haswell
2 x Intel E5-2680v3
|
Ivy Bridge
2 x Intel E5-2697v2
|
| # cores per nodes | 24 | 24 |
| # nodes | 240 | 342 |
| Total # of cores | 5760 | 8208 |
| Processor speed | 2.5 GHz | 2.7 GHz |
| Instruction Set Extensions | AVX2.0 | AVX |
| Cache | 30MB shared by 12 cores | 30MB shared by 12 cores |
| Memory size per node |
64 GB (218 fit)
128 GB (18 fat)
256 GB (4 xfat)
|
64 GB |
| Memory size per core |
2.67 GB (fit)
5.34 GB (fat)
10.68 GB (xfat)
|
2.67 GB |
| Memory Type |
DDR4 @ 2133 MHz (fit & fat)
|
DDR3 @ 1866 MHz |
| Memory bandwith | 68.2 GB/s read/write | 59.7 GB/s read/write |
| Ethernet | Gigabit Ethernet | Gigabit Ethernet |
| Host Channel Adapter | Mellanox Connect-IB single FDR | Mellanox ConnectX3 single FDR |
| Local disk | 1 SSD 128 GB | 1 SSD 64 GB |
- Manufacturer: Bull Atos
- 2 servers R421-E3
| Nodes details | |
|---|---|
| Blade type | Bullx R421-E3 |
| Node type | Ivy Bridge 2x Intel E5-2697v2 |
| # cores per nodes | 24 |
| # nodes | 2 |
| Total # of cores | 48 |
| Processor speed | 2.7 GHz |
| Cache | 30MB shared by 12 cores |
| Memory size per node | 256 GB |
| Memory size per core | 10.68 GB |
| Memory Type | DDR3 @ 1866 MHz |
| Memory bandwith | 59.7 GB/s read/write |
| Ethernet | Gigabit Ethernet |
| Host Channel Adapter | Mellanox ConnectX3 single FDR |
| PCIe | 2x slots PCIe 3.0x16 dedicated to graphic cards 1x slot PCIex8 |
| GPU | 2x nVidia K40 |
| Local disk | 2x SATA3 500GB |
| nVidia K40 details | |
| Processor | 1 processor GK110B |
| # cores | 2880 |
| Frequency | Base clock: 745Mhz Boost clock: 810MHz and 875MHz |
| Memory size | 12GB |
| Memory I/O | 384bit GDDR5 |
Gigabit Ethernet Network
The Ethernet network interconnects all the entities of the cluster and is used for administrative tasks (installation, management, supervision, NFS, PBS communications,...).
Infiniband Network
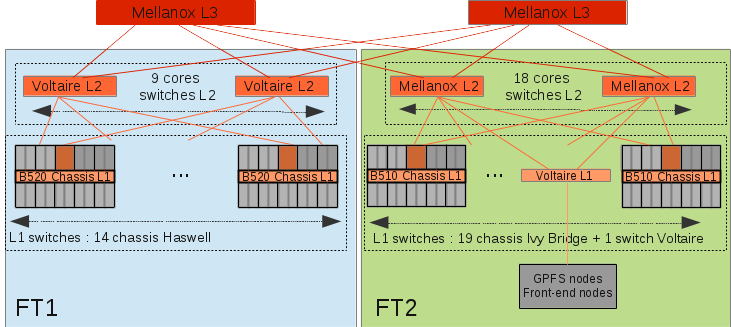
The infiniband network is made of 63 switches: 1 per chassis, 10 Voltaire QDR ISR-036 and 20 Mellanox QDR IS5030 switches.
The infiniband network is composed of 3 levels: the Leaf level (L1), the Core level (L2) and the Top level (L3).
The higher level, L3, connects 2 non-blocking fat-tree which include:
- FT1: 14 Haswell nodes chassis;
- FT2: 19 Ivy Bridge nodes chassis + frontal nodes + GPFS nodes.
Inside each fat tree, communication between entities are non-blocking and between the two fat-trees, communications are blocking. The link between the L3 switches has been designed to satisfy the GPFS traffic but not to support computation between the two blocks.
- Network File System (NFS) on a NetApp FAS2040 equipped with 3 DS4243 drawers, with a total of 84 disks for 116 TB net space split across multipe volumes.
- IBM's General Parallel File System (GPFS) on 4 Bull R423-E2 IO servers connected to 4 LSI 2600-HD SAN arrays equipped with a total of 240 disks for 350 TB net space on a single volume.
- Operating System: Red Hat Enterprise and CentOS Linux release 6.5
- Job Scheduler: Altair PBS Professional
- Web Portal: BULL eXtreme Computing Studio (XCS)
- Compilers: Intel and GNU C, C++ and Fortran
- MPI: Intel MPI and OpenMPI
Access and Accounting
Getting access
Please refer to this page.
Web Portal login
Once you received your credentials, you should be able to access zenobe through the portal.hpc.cenaero.be web interface with your zenobe login and password.
Console login
-
Academic users
Once your access has been validated by the CÉCI adminstrators, the Tier-1 calculator's administrators will create your account and send you an e-mail notification, you should then be able to connect to the HPC using an SSH client. All of the information on how to connect to the system is available on the CÉCI's website.
-
Other users
Once you received your credentials, you should be able to access zenobe through the hpc.cenaero.be SSH gateway.
Linux and Mac OS users
- First, connect to the hpc.cenaero.be SSH gateway using the provided login and password:
ssh mylogin@hpc.cenaero.be - then, connect to zenobe's the frontal node by using the following command:
ssh mylogin@zenobe
Windows users
- First, use an SSH client (like PuTTY)
- The host is hpc.cenaero.be
- Enter the provided login and password
- Once logged on the hpc.cenaero.be gateway, you can connect to the frontal node by using the following command:
ssh mylogin@zenobe
- First, connect to the hpc.cenaero.be SSH gateway using the provided login and password:
Jobs Accounting Metric
The jobs accounting is based on the R_Wall_Time metric that accounts for the resources actually mobilized by the jobs.
The metric definition is: R_Wall_Time = Wall_Time * ncpus_equiv_pjob
where:
- Wall_Time is the execution time of the job (end_time - start_time - suspend_time);
- and ncpus_equiv_pjob is defined as follows:
- if the job is run in an exclusive queue or environment, complete nodes are associated to your job, and then
ncpus_equiv_pjob = nodes_pjob * ncpus_pnode - else the job is run in a shared mode (sharing nodes with other jobs or projects) and then
ncpus_equiv_pjob = max ( ncpus_pjob , mem_pjob / mem_pcpu )
- if the job is run in an exclusive queue or environment, complete nodes are associated to your job, and then
in which:
- ncpus_pnode is the number of cores available per node
- ncpus_pjob and mem_pjob are respectively the total number of cores and total amount of memory requested by the job (respectively resource_list.ncpus and resource_list.mem reported in a qstat -f on the job) and
- mem_pcpu is the amount of memory available per core depending on the type of node requested, i.e.
- 2625MB by default (Haswell fit nodes)
- 5250MB if you requested Haswell fat nodes ( -l model=haswell_fat )
- 10500MB if you requested Haswell xfat nodes ( -l model=haswell_xfat )
ncpus_equiv_pjob is the resource_used.rncpus value reported in a qstat -f on the job.
See also Job Output file to check resource usage of the job.
Reservation or Dedicated Nodes Accounting
R_Wall_Time accounted is:
(Reservation end_time - Reservation start_time) * Number of Dedicated Nodes * ncpus_pnode.
Reporting
Reports are sent weekly and monthly to project managers. Persistent and scratch storage usages and some job statistics are provided with the R_Wall_time credit used during the period by queue and/or globally and the remaining credit.
Some ratios are also provided:
- η = Total CPU_Time / ( Total Wall_Time * NCPUS_PJOB )
- α = Total CPU_Time / ( Total Wall_Time * NCPUS_EQUIV_PJOB )
Example:
|
======================================================================================
Project created Friday Oct 31 2014 ====================================================================================== SCRATCH storage quota : 400 GiB SCRATCH storage used : 196 GiB Persistent storage quota : 200 GiB Persistent storage used : 48 GiB ------------------------------------------------------------------------------------- Job Usage Detail (times in hours) user1 3 8.7 1.0 10.6 82.1% 10.6 82.1% 0.0 Job Set Summary (times in hours) R_Wall_Time Credit allocated : 31000 hours |
Credit management
Project managers are kindly requested to monitor their project resources usage. Projects with a negative remaining credit will have one month to update their request; after this delay, jobs associated to these projects will be rejected. Academic users can always update their project credit via the following page https://login.ceci-hpc.be/init-project/. Other users can send an email to it![]() cenaero [dotcenaero] be.
cenaero [dotcenaero] be.
Papers published thanks to results obtained from zenobe must include the following paragraph in the appropriate "Acknowledgement" section:
"The present research benefited from computational resources made available on the Tier-1 supercomputer of the Fédération Wallonie-Bruxelles, infrastructure funded by the Walloon Region under the grant agreement n°1117545."
If the paper is published in French, use the following:
"Les présents travaux ont bénéficié de moyens de calcul mis à disposition sur le supercalculateur Tier-1 de la Fédération Wallonie-Bruxelles, infrastructure financée par la Région wallonne sous la convention n°1117545."
Data Storage organisation
Structure
Home directory
When you login on the supercomputer, you are directly redirected to /home/organization/username. This space is only there for personnal data and configurations.
Projects directory
This data space is only reserved for the data persistent through the time life of the project and potentially common to the project members : typically, particular software or files that need to be kept after a job is completed. To access this space, go to /projects/organization/project_name.
Scratch directory
This space is made for 2 types of data and only for temporary files:
- Users data: All the data that require a bigger space. Accessible from /SCRATCH/organization/username;
- Projects data: When you run a job, the data has to be stored first here. Accessible from /SCRATCH/organization/project_name.
Be careful: the data on this storage can be deleted at any time without any warning from the supercomputer admin.
Nodes local storage
Each compute node has a local SSD disk which is dedicated administration tasks. The local disk is not available for computation.
Systems details
NetApp
Quotas are set per user on /home and per project (managed by unix group) on /projects. The home directories are set as follow:
| Configuration | ||||
| Volumes name | Default quota (soft/hard) | |||
| /home | 30/35 Go | |||
| /home/acad | 50/50 Go | |||
The quota for the projects needs to be identified before starting it, as you can see by default no space are allocated to the project. There is no method to check by yourself the quota, so if you have doubts, please contact it![]() cenaero [dotcenaero] be.
cenaero [dotcenaero] be.
Currently, there is no backup on this volume.
Snapshots are done for /home, /projects and /softs. For /home and /projects, they are taken nightly at midnight and hourly at 8:00, 12:00, 16:00 and 20:00. The 6 last hourly and the 2 last nightly snapshots are kept. For /softs only the 1 nightly is kept.
GPFS
| Configuration | |
| /SCRATCH | 350 To |
Quotas are set per project (managed by unix group) and per organizational group. GPFS is reliable but data are not backed up.
In this volume you can check by yourself the quota for a project. To do that enter the following command line into the frontend system:
mmlsquota -g <PROJECTNAME>
The output of this command will be something like that :
|
Disk quotas for group PROJECTNAME (gid xxxx):
Block Limits | File Limits |
For now, the hard limit (named limit in the above line) is at 30% of the soft limit (named quota in the above line)
Web Portal
- Web Portal is slow. Users have to wait several minutes in order to obtain status of their jobs.
- Reservations are not available.
- Job arrays are not supported.
- Jobs accounting information is not relevant as it does not take into account ncpus_equiv_pjob metric (see Accounting)
- Project disk usage is not relevant.
- User can only upload files in the Upload directory located in his home directory.
- Only TurboVNC or XRV are supported for visualisation session.
Software Libraries
User- and project-specific packages
Users can install tools in their home or project directory with respect to their quotas, but it is a good idea to discuss with the HPC and Infrastructure team in order to optimize the collaborative work, not duplicate applications and save disk space.
Standard Software
Shared tools and applications are installed in the /softs partition.
Note that the access to commercial software is restricted (Samcef, Abaqus, Ansys, Fluent, Morfeo, elsA,...).
New software can be installed with the agreement and collaboration of the HPC and Infrastructure team.
Software Environment Management
The Environment Modules package provides for the dynamic modification of a user's environment via modulefiles.
When you log in, no modules are loaded by default.
To see all available modules, issue the following command: $ module avail
It displays a complete list of modules that are available to be loaded into your environment.
You can load, unload, and even swap/switch modules using the module command:
|
$ module load
$ module unload $ module switch |
To see which modules you currently have loaded, issue the following command: $ module list
To display a list of environment variables and other information about an individual module "module_name", invoke the following: $ module show <module_name>
To remove all modules from the environment use: $ module purge
For advanced topics use: $ module help
This is a non-exhaustive list of software maintained on Zenobe in /softs.
To check available supported software, issue the command :$ module avail
| Type | Name | Versions |
|---|---|---|
| Compilers | GNU Compilers | 4.1.2 |
| 4.4.4 | ||
| 4.4.7 | ||
| 4.6.4 | ||
| 4.7.4 | ||
| 4.8.4 | ||
| Intel Compilers | composerxe/2011.7.256 | |
| composerxe/2013.2.146 | ||
| composerxe/2013_sp1.1.106 | ||
|
composerxe/2015.1.133 |
| Type | Name | Versions |
|---|---|---|
| Message Passing Interface | ||
| OpenMPI - RedHat6 | 1.4.5 | |
| 1.6.5 | ||
| 1.8.4 | ||
| IntelMPI | 4.0.3.008 | |
| 4.1.0.024 | ||
| 4.1.0.030 | ||
| 4.1.1.036 | ||
| 4.1.3.045 | ||
| 5.0.2.044 |
| Type | Name | Versions |
|---|---|---|
| Parrallel Tools | Intel Develoment Tool Suite | Vtune_amplifier_XE 2013 |
| Vtune_amplifier_XE 2015.1.1 | ||
| Advisor_XE 2013 | ||
| Advisor_XE 2015.1.10 | ||
| Inspector_XE 2013 | ||
| Inspector_XE 2015.1.2 | ||
| Itac 8.1.0.024 | ||
| Itac 8.1.4.045 | ||
| Itac 9.0.2.045 | ||
| Allinea | 3.1-21691-Redhat-5.7 | |
| 4.1-32296-Redhat-5-7 | ||
| 4.2.1-36484-Redhat-6.0 | ||
| Scalasca (+ cube 4.2.1) | intelmpi-4.1.3-045 | |
| openmpi-1.4.5 | ||
| openmpi-1.6.5 | ||
| TAU | intelmpi-4.1.3.045 | |
| openmpi-1.4.5 | ||
| openmpi-1.6.5 | ||
| Scorep | intelmpi-4.1.3.045 | |
| openmpi-1.4.5 | ||
| openmpi-1.6.5 | ||
| PAPI | 5.3 gcc 4.4.7 | |
| Likwid | 3.0.0 | |
| 3.1.1 |
Compiling and Linking
Software porting :
Intel Composer 2015 update 5 is the recommended compiler (currently the latest Intel compiler installed on zenobe).
- The instruction set is upward compatible. Therefore:
- Applications compiled with -xAVX can run on ivy Bridge, or Haswell processor
- Applications compiled with -xCORE-AVX2 can run only on Haswell processors
- Generating optimized code for Haswell processors
- If your goal is to achieve the best performance from the Haswell processors, use the latest Intel compiler with one of the following the Haswell-specific optimization flags:
-axCORE-AVX2
-xCORE-AVX2
Running an executable built with either the -xCORE-AVX2 flag or the -axCORE-AVX2 flag on Ivy Bridge processors will result in the following error:
Fatal Error: This program was not built to run in your system. Please verify that both the operating system and the processor support Intel(R) AVX2 - Generating code for any processor type
If your goal is to create a portable executable file that can run on any processor type, you can choose one of the following approaches:
Use none of the above flags (which defaults to -mSSE2)
Use -xAVX
Use -O3 -axCORE-AVX2 -xAVX (with the latest Intel compiler) Libraries built by ourselves (hdf5,....) are not yet optimized for Haswell processors.
- If your goal is to achieve the best performance from the Haswell processors, use the latest Intel compiler with one of the following the Haswell-specific optimization flags:
MPI
Intel MPI and OpenMPI librairies are available on Zenobe.
OpenMPI are compiled with gcc 4.1.2 unless those tag with “-el6” which are built with gcc 4.4.7. Use module command to list the different releases.
The recommended tool is Intel MPI 4.1.3.045.
Prior to using an MPI library, you will have to load an appropriate module for a supported compiler suite.
Debug
Debugging your application gdb (gcc 4.4.7 tool suite ), Intel idb provided with Intel Composer XE tools suite and Allinea DDT are available for debugging purpose. Use module command to list the different releases.
Performance analysis
Tuning your application Allinea MAP and Intel Cluster Studio XE tools suite are available for tuning purpose. Use module command to list the different releases.
TAU, PAPI, SCALASCA and likwid installations are not finalized yet.
Queueing and Running Jobs
Golden Rules
- Any computation tasks must be launched through the scheduler.
- Use resources efficiently.
- ssh on a compute node is allowed for debugging and monitoring purpose only when users have a running job on this node.
Scheduling
- Jobs are scheduled by jobs priority, this priority is computed based on group/project faireshare usage.
- Strict_ordering: runs jobs exactly in the order determined by the scheduling option settings, i.e. runs the "most deserving job" as soon as possible.
- Backfill: allows smaller jobs to be scheduled around more deserving jobs.
- Sharing: jobs share nodes by default except if it is explicitly specified in the queue (see queue large) or in the job requirements.
- Quarterly maintenance window (dedicated time): to be confirmed 1 month prior to the maintenance.
Jobs
- Jobs that alter the sake of optimal global functioning of the cluster or that negatively impact other jobs through an abnormal resources usage will be killed.
- HPC administrators will wait 12 hours prior to do a non-crucial intervention and stop jobs.
- We require that jobs which walltime lasts more than 12 hours must be re-runnable.
- Re-runnable means that the job can be terminated and restarted from the beginning without harmful side effects (PBS Reference guide terminology).
- This must be materialized in your PBSpro script by the directive:
#PBS -r y - In case of cancellation (node crash, operator intervention,...) re-runnable jobs will be automatically resubmitted by PBSpro and they may belong to one of the following cases:
- Worst case:
- 1. The job is actually not re-runnable (for instance it is influenced by the output of a previous run in an uncontrolled manner) and will most probably crash (possibly corrupting generated results). The job's owner knows and accepts it;
- 2.The job is not restartable but it is not influenced by previous output files, then it will rerun automatically from the beginning (and the job's owner knows and accepts it);
-
Ad hoc case: The job's owner is ready to take manual actions to make sure the input and previous output files are adapted adequately for the restart. Then, insert at the beginning of the PBS script, just after the PBS directives:
qhold -h u $PBS_JOBID
In the case of cancellation and rerun, the PBS server will put the job on hold. At this step, after the modification of your data, you can release the job with theqrlscommand. - Ideal case: The job does modify the input files and/or checks the output generated by a previous run adequately. In the case of cancellation and rerun, the job will restart and continue automatically from the last checkpoint.
- Worst case:
- Running job on the front-end node is not allowed.
- Using Haswell and Ivy Bridge nodes in a same job is not allowed.
Project
- Computing hours and disk credits are allocated by project. A project has always a start date and an end date.
- Project can be extended on demand and with justifications.
- If not:
- At the end date, the project is closed. New jobs are not allowed.
- Three months after the end of project, the remaining data in project directories will be cleared.
- Jobs submission is only allowed through project. In order to do accounting and to work with the resources (walltime, ncpus, disk space,…) allocated to the project <project_name>, add in your PBSpro script, the directive:
#PBS -W group_list=<project_name>
The different queues are organized to follow the different hardware and usages:
-
large: This queue is a routing queue dispatching jobs in execution queue, large_ivy. It addresses jobs only to Ivy Bridge nodes and is dedicated to large massively parallel jobs. Following limits are applied to this queue:
- Job placement on nodes is exclusive.
- Minimum number of cpus per job = 96
- Maximum number of cpus per job = 4320
- Walltime maximum = 24 hours
-
main: This is the default queue.
- Following limits are applied to main queue:
- Walltime maximum = 168 hours
- Maximum number of cpus per job = 192
- The main queue is a routing queue dispatching jobs in execution queues:
- main_has: default execution queue. It addresses jobs only to fit or fat Haswell nodes (accounting based on fit nodes). Nothing to add.
- Following limits are applied to this execution queue:
- Maximum number of cpus per user = 480
- Maximum number of cpus per project = 960
- Following limits are applied to this execution queue:
- main_has_fat: It addresses jobs only to fat Haswell nodes (accounting based on fat nodes). To use this queue, add:
#PBS -l model=haswell_fat - main_has_xfat: It addresses jobs only to xfat Haswell nodes (accounting based on xfat nodes). To use this queue, add:
#PBS -l model=haswell_xfat
- main_has: default execution queue. It addresses jobs only to fit or fat Haswell nodes (accounting based on fit nodes). Nothing to add.
- Do not submit jobs directly in the execution queues.
- Job placement on nodes in queue main is shared.
- Following limits are applied to main queue:
-
visu: This queue is a routing queue dispatching visualisation jobs on the 2 graphic nodes. Each visualisation session can required at maximum: 12 cores, 126000MB of memory and 1 GPU.
- execution queues:
- visu2: It addresses jobs to the available GPU of each virtual node
- Do not submit jobs directly in the execution queues.
- execution queues:
- Restricted access queues: zen, diags, or ded_ for dedicated time, ...
- Reservation can be done by the support on demand.
Check the queue properties and limits with the command:qstat -Qf
The cstat command (non standard) displays nodes/queues jobs repartition.
Zenobe supercomputer uses the Portable Batch System (PBS) from Altair for job submission, job monitoring, and job management. Current release is 13.1.2.
Batch and Interactive jobs are available. Interactive jobs can be particularly useful for developing and debugging applications.
Basic Commands
The most commonly used PBS commands, qsub, qdel, qhold, qalter and qstat are briefly described below. These commands are run from the login node to manage your batch jobs.
See PBS Reference manual for a list of all PBS commands
qsub
The qsub is used to submit a job to the batch system.
- To submit a batch job script:
qsub [options] my_script - To submit a batch job executable:
qsub [options] my_executable [my_executable_arguments] - To submit a interactive job:
qsub -I [options] - To submit a job array:
qsub -J <num-range> [options] script or executable
Most common options:
| Input/output | |
|
-o path |
standard output file |
| -e path | path standard error file |
| -j oe (eo) | joins standard error to standard output (standard output to standard error). oe is the default. |
| Queue | |
| -q <queue_name> | runs jobs in queue <queue_name> |
| Notification | |
| -M email address | notifications will be sent to this email address |
| -m b|e|a|n | notifications on the following events: begin, end, abort, no mail (default) Do not forget to specify an email address (with -M) if you want to get these notifications. |
| Resource | |
| -l walltime=[hours:minutes:]seconds | requests real time; the default is 12 hours. |
| -l select=N:ncpus=NCPU | requests N times NCPU slots (=CPU cores) for the job (default for NCPU: 1) |
| -l select=N:mem=size | requests N times size bytes of memory for each chunk (default is 1GB). |
| -l pmem=size | request a maximum of size bytes of memory for all processes of the job. |
| -l model=<model_type> | request fit, fat, xfat Haswell nodes when allowed in the queue. |
| -l place= | chooses the sharing, grouping and the placement of nodes when it is allowed in the queue (default is free). |
| Dependency | |
| -W depend=afterok:job-id | starts job only if the job with job id job-id has finished successfully. |
| Miscellaneous | |
| -r y|n |
notifies that job is rerunnable (default no) |
| -v | specifies the environment variables and shell functions to be exported to the job. |
| -V | Declares that all environment variables and shell functions in the user's login environment where qsub is run are to be exported to the job. |
qdel
To delete a job:qdel <jobid>
qhold
To hold a job:qhold <jobid>
Only the job owner or a system administrator can place a hold on a job. The hold can be released using the qrls <jobid> command.
qalter
The qalter command is used to modify attributes of one or more PBS queued (not running) jobs. The options you can modify are a subset of the directives that can be used when submitting a job. A non-privileged user may only lower the limits for resources.qalter [options] <jobid>
qstat
To display queue information:qstat -Q
Common options to display job information :
-aDisplay all jobs in any status (running, queued, held)-rDisplay running jobs-u <username>Display user username jobs-f <jobid>Display detailed information about a specific job-xf <jobid>Display detailed information about a finished specific job (within past 48 hours)-TDisplay estimated start time-wDisplay information in a wide format
PBS Environment Variables
Several environment variables are provided to PBS jobs. All PBS-provided environment variable names start with the characters "PBS_". Some start with "PBS_O_", which indicates that the variable is taken from the job's originating environment (that is, the user's environment).
A few useful PBS environment variables are described in the following list:
| PBS_O_WORKDIR | Contains the name of the directory from which the user submitted the PBS job |
| PBS_O_QUEUE | Contains the queue name |
| PBS_JOBID | Contains the PBS job identifier |
| PBS_NODEFILE | Contains a list of nodes assigned to the job |
| PBS_JOBNAME | Contains the job name |
Writing a submission script is typically the most convenient way to submit your job to the job submission system but jobs can also be submitted on the command line. A job script consists of PBS directives, comments and executable commands.
A PBSpro script is composed of 3 parts:
- Shell (PBSpro always executes the shell startup script)
- PBSpro directives
- Instructions set of your code
Example:
|
#!/bin/csh
#PBS -j oe #PBS -N HPLtest #PBS -l walltime=1:00:00 #PBS -l select=1:ncpus=24:mem=63000mb:mpiprocs=1:ompthreads=24:cenaero=z_has #PBS -W group_list=PRACE_T1FWB #PBS -r y echo "------------------ Work dir --------------------" source /usr/share/Modules/init/csh setenv name `eval hostname` echo -n "This run was done on: " >> $OUT |
Resource types and chunk
PBS resources represent things such as CPUs (cores), memory, switches, hosts, Operating System, chassis, time.... They can also represent whether or not something is true or not, for example whether a node is dedicated to a particular project or group.
A chunk is a set of resources that are allocated as a unit to a job. All parts of a chunk come from the same host/node.
A chunk-level resource or a host-level resource is a resource available at host level. The resources of a chunk are to be applied to the portion of the job running in that chunk. Chunk resources are requested inside a select statement.
Chunk level resources that can be requested are: ncpus, mpiprocs, ompthreads, mem, chassis, host,...
Check chunk resources available with the pbsnodes command:pbsnodes <node_name>
Job-wide resource, also called queue-level or server-level resource, is a resource that is available to the entire job at the server or the queue.
Job-wide resources that can be requested are: walltime, pmem, place
Format for requesting job-wide resources:qsub … (non-resource portion of the job) -l resource=value
Format for requesting chunk resources:qsub … (non-resource portion of the job) -l select=[N:][chunk specification][+[N:]...]
where N is the number of identical chunks, + adds a new set of identical chunks.
PBS assigns chunks to job processes in the order in which the chunks appear in the select statement.
Memory resource
| The memory per node available for computation is limited to the following values: |
| Ivy Bridge and Haswell fit nodes: | 63000MB |
| 18 Haswell fat nodes: | 126000MB |
| 4 Haswell xfat nodes: | 252000MB |
| The ideal memory per process is : |
| fit nodes: | 2625MB |
| fat nodes: | 5250MB |
| xfat nodes: | 10500MB |
The memory lower bound is 256MB. Jobs requesting less than 256MB per chunk will be put on hold (system) by the PBS enforcement tools with the message CgroupLimitError.
Placement
Users can specify how the job should be placed on nodes. Users can choose to place each chunk on a different host, or to share a specific value for some resource.
The place statement must be used to specify how the job's chunk are placed. The place statement has the form:qsub … -l place=[arrangement][:sharing][:grouping]
where
- arrangement is one of free | pack | scatter| vscatter
- sharing is excl | shared | exclhost
- grouping can have only one instance group=resource
Examples:
Academic users (and others) can find a useful script generation wizard on the CÉCI web site.
Below are some other specific examples:
- You want five identical chunks requesting twelve CPUS and 43000MB of memory each, placed on different nodes:
qsub … -l select=5:ncpus=12:mem=43000mb -l place=scatter - You want four chunks, where the first has two CPUs and 20GB of memory, the second has 4 CPUs and 4GB of memory and the two last ones, one CPU and 40GB of memory with a free placement:
qsub … -l select=1:ncpus=2:mem=20GB+1:ncpus=4:mem=4GB+2:ncpus=1:mem=40GB …
Some resources or placement can be requested by users, other ones are read-only and cannot be modified by users (queues limits).
Cpus and memory enforcements
Cpus and memory are enforced on zenobe with "cgroups". The term cgroup (pronounced see-group, short for control groups) refers to a Linux kernel feature that was introduced in version 2.6.24. A cgroup may be used to restrict access to system resources and account for resource usage. The root cgroup is the ancestor of all cgroups and provides access to all system resources. When a cgroup is created, it inherits the configuration of its parent. Once created, a cgroup may be configured to restrict access to a subset of its parent’s resources. When processes are assigned to a cgroup, the kernel enforces all configured restrictions. When a process assigned to a cgroup creates a child process, the child is automatically assigned to its parent’s cgroup.
On zenobe Linux cgroups implementation in PBSpro scheduler do the following:
- Prevent job processes from using more resources than specified; e.g. disallow bursting above limits
- Keep job processes within defined memory and CPU boundaries
- Track and report resource usage
Cgroups are not set by chunk but by node/host. If PBS can put several chunks of a job on the same node, these resources will be all attached to the same cgroup.
Within the memory cgroup, the memory management is based on the Resident Set Size, ie the physical memory used. Use mem or pmem to request the job resources.
When a job is killed due to hitting the memory cgroup limit, you will see something like the following in the job's output:
Cgroup memory limit exceeded: Killed process ...
Job Lifecycle with Cgroups
When PBS runs a single-host job with Cgroup, the following happens:
- PBS creates a cgroup on the host assigned to the job. PBS assigns resources (CPUs and memory) to the cgroup.
- PBS places the job’s parent process ID (PPID) in the cgroup. The kernel captures any child processes that the job starts on the primary execution host and places them in the cgroup.
- When the job has finished, the cgroups hook reports CPU and memory usage to PBS and PBS cleans up the cgroup.
When PBS runs a multi-host job, the following happens:
- PBS creates a cgroup on each host assigned to the job. PBS assigns resources (CPUs and memory) to the cgroup.
- PBS places the job’s parent process ID (PPID) in the cgroup. The kernel captures any child processes that the job starts on the primary execution host and places them in the cgroup.
- MPI jobs:
- As PBS is integrated with IntelMPI and OpenMPI. PBS places the parent process ID (PPID) in the correct cgroup. PBS communicates the PPID to any sister MoMs and adds them to the correct group on the sister MoM.
- For MPI jobs that do not use IntelMPI or OpenMPI, please contact it
 cenaero [dotcenaero] be to verify the program behavior.
cenaero [dotcenaero] be to verify the program behavior.
- Non-MPI jobs: we must make sure that job processes get attached to the correct job. Please contact itcenaero [dotcenaero] be to verify the program behavior.
- MPI jobs:
- When the job has finished, the cgroups hook reports CPU and memory usage to PBS and PBS cleans up the cgroup.
Node Access Enforcement
- Users who are not running PBS jobs cannot access to the compute nodes.
- At the end of the job PBS output file,
- First, information logged by the server during the last 2 days is provided.
- Second, master and slaves nodes information logged by the cpuacct cgroup subsystem follows. Pay attention to memory and cpu time used on each node.
- Third, a summary of the resources requested and used is provided. See Accounting for metrics definition.
- Exit codes:
- Exit Code = 0: Job execution was successful.
- Exit Code < 0: This is a PBS special return indicating that the job could not be executed. (See PBS documentation for more details and contact support).
- Exit Code between 0 and 128 (or 256) : This is the exit value of the top process, typically the shell. This may be the exit value of the last command executed in the shell.
- Exit Code >= 128 or 256: This means the job was killed by a signal. The signal is given by X modulo 128 ( or 256). If a job had an exit status of 143, that indicates the job was killed with a SIGTERM ( e.g. 143 - 128 = 15 ). See kill(1) man page for signal definitions.
- Do not send the output of the software in the PBS output file. The PBS output file is kept on the job master node /var/spool/PBS/spool directory and copied back at the end of the job in the user's directory where the job was launched.
- Example:
|
----------------- PBS server and MOM logs ----------------- ------------------frontal2.cenaero.be------------------ Job: 915424.frontal2 03/06/2017 19:55:08 S enqueuing into main, state 1 hop 1 ------------------node0851------------------ Job: 915424.frontal2 03/06/2017 19:55:09 M running prologue ------------------node0852------------------
03/06/2017 19:55:09 M JOIN_JOB as node 1 ------------------------------- Job Information ------------------------------- Job Owner : coulon@frontal3 Resources Requested Number of Cores per Job - NCPUS_PJOB : 48 Resources Used Total Memory used - MEM : 64963112kb For metrics definition, please refer to https://tier1.cenaero.be/en/faq-page -------------------------------------------------------------------------------
|
Job's Nodes File
For each job, PBS creates a job-specific “host file” which is a text file containing the name of the nodes allocated to that job, one per line. The file is created by PBS on the primary execution host and is only available on that host. The order in which hosts appear in the node file is the order in which chunks are specified.
The full path and name for the node file is set in the job's environment variable $PBS_NODEFILE.
MPI
The number of MPI processes per chunk defaults to 1 unless it is explicitly specified using the mpiprocs resource. Open MPI and IntelMPI automatically obtain both the list of hosts and how many processes to start on each host from PBS Pro directly through the $PBS_NODEFILE. Hence, it is unnecessary to specify the --hostfile, --host, or -np options to mpirun if the MPI software default interpretation of this file corresponds to what you want. For example:
- IntelMPI : default is hostfile which means that duplicated hostname lines are removed.
- OpenMPI : The reordering of the lines is performed in order to group the same nodes.
Open MPI and IntelMPI versions installed on zenobe use PBS mechanisms to launch and kill processes. PBS can track resource usage, control jobs, clean up job processes and perform accounting for all of the tasks run under the MPI.
OpenMP
PBSpro supports OpenMP applications by setting the OMP_NUM_THREADS variable in the job's environment, based on the request of the job.
If ompthreads is requested, OMP_NUM_THREADS is set to this value, if ompthreads is not requested, OMP_NUM_THREADS is set 1.
For the MPI process with rank 0, the environment variable OMP_NUM_THREADS is set to the value of ompthreads. For other MPI processes, the behavior is dependent on MPI implementation.
Usage Cases:
- Mono-processor jobs
- OpenMP jobs
- MPI jobs
- Hybrid MPI/OpenMP jobs
- Jobs Array
- Homogeneous/ Heterogeneous Resources
- Embarassingly parallelism: pbsdsh
FAQ
The first one relies on the visualization portal installed on Zenobe.
The second one relies on a manual configuration of a ParaView server and its connection to a ParaView client.
Supercomputer under maintenance
Every three months, we planned a maintenance between 7AM and 7PM. During this maintenance the supercomputer is unreachable.
You are not allowed on our system
please see the section Login and Access in this page.
Undefined problem
Please contact it![]() cenaero [dotcenaero] be.
cenaero [dotcenaero] be.
Wrong permission on your directory
To avoid any fake error "quota exceeded" on /project/organization/projectsName and on /SCRATCH/organization/projectsName, please check the permission on your directories. The setGID need to be set for the group so the line has to be something like that :
drwxr-sr-x 2 MyUsername GroupProjects 4096 Oct 16 2015 myDirectories
If this lowcase "s" is not set to the group part, please make a : chmod g+s directory
Once you modified the permission make sur the owners is correctly specified. The group has to be the project on which the directory is related.
This kind of problem can be triggered by a move into the directory. When you make a move from your home directory (for example), the directory keeps its permission, so when you want move some directories, please use the following command :
cp -r fromDirectory toDirectory
By using this command, the directories will have the correct permissions.
If you want more information about setGID, please use the following command : man chmod. In this manual, there is a specific section about the "special" permissions
General points
If the above solution is not applicable, please check if you can safe some spaces by cleaning your data.
If needed a modification of the /SCRATCH or /projects quota can be done (only for projects)
Academic users
The project's manager has to send a request to the CÉCI Admin through this link.
Others users
You have to send a request to it![]() cenaero [dotcenaero] be after reevaluation of the need. If you need assisstances for this kind of reevaluation, don't hesitate to contact the HPC admin (it
cenaero [dotcenaero] be after reevaluation of the need. If you need assisstances for this kind of reevaluation, don't hesitate to contact the HPC admin (it![]() cenaero [dotcenaero] be)
cenaero [dotcenaero] be)
